Apr 23, 2014
![]()
The Journey Begins

A little over a year ago I was frustrated with the lack of data meetups in the Philadelphia area, so I started DataPhilly. I quickly learned that when you start a tech meetup you’re going to have to do some public speaking to get the ball rolling. I was DataPhilly’s first speaker because no one else volunteered to present at the first meeting. Even though I’d had the opportunity to practice public speaking several times prior to this as part of our weekly Tutorial Tuesday series at AWeber, my first talk for DataPhilly felt really rough. Despite this, DataPhilly quickly gained steam, and we’ve had a ton of excellent speakers and fantastic talks. Since then I’ve had the opportunity to speak at both DataPhilly and PhillyPUG.

Last July I was fortunate enough to speak at PyData in Boston where I learned an important lesson; do not commit to delivering more than one talk at a conference. Giving two talks back to back was a bit much, but like my first talk at DataPhilly, I made it through and learned a lot in the process.
PyCon
After my experience at PyData, I decided to submit a talk to PyCon. I became anxious waiting to see if my talk would be accepted, so I decided to hack the process a bit. I wanted to gain insight into the PyCon planning process, and so I joined the PyCon Program Committee. One really cool thing about the PyCon planning process is that anyone can get involved! With the number of submissions growing each year, I encourage anyone interested to volunteer. It doesn’t take a lot of time (really you can devote as little or as much time as you can spare), and it is a great way to give back to the community. On top of this, you’ll help decide which talks get accepted at the next PyCon!
Only one in seven talks submitted were selected by the program committee for PyCon this year. A lot of great talks were rejected, and I feel very lucky that my submission made the cut. Being picked to speak at such a selective conference is truly an honor!
The Speaking Experience
Speaking at PyCon was made really simple by the awesome staff of volunteers and A/V crew. A green room is provided for speakers so they can hide from their fans and prepare for their talks. One cool side-effect of this is that, as a speaker, you get to hang out with all these famous people from the Python scene. I got to personally thank Fernando Pérez (the creator of IPython, not the baseball player) for his hard work on IPython. Fernando was very humble about his work and gave credit to the rest of the IPython community rather than taking credit for himself. This was a common theme at PyCon. All of the “big name” people I talked to seemed equally as humble. It seems that the Python community is not a place for egos, and that’s really refreshing. I suppose part of this is the nature of open source projects. Those projects started by people who seek inclusiveness are the most successful. An important part of this is sharing credit with others. So it only makes sense that many successful open source projects have a BDFL whom is humble and honest about their own part in the effort.
Keynotes
All the of the keynotes were excellent but I especially enjoyed the keynotes by Guido Van Rossum, Jessica McKellar and Fernando Pérez.
Diversity in Tech
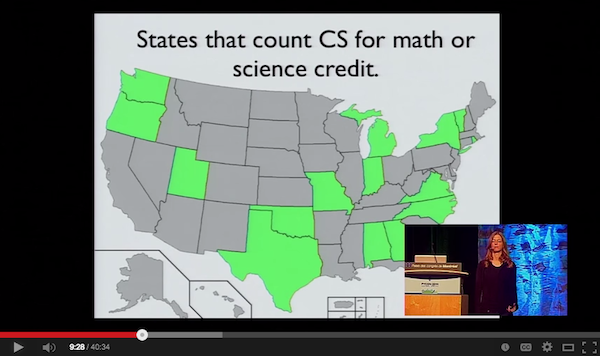
Jessica gave an excellent talk about teaching computer science to the next generation and how to fix the diversity gap in the tech community. She talked about how so few high school students are taking the AP computer science exam. “There are entire states in the United States where no African-American students take the exam at all. There are states where no Hispanic students have taken the exam. And, despite being 50 percent of the population, there are even states where no girls took the exam”. Despite the fact that the President of the United States of America believes that it is important for children to learn to code, in many school districts, there isn’t even a computer science class offered to high school students. Jessica’s talk continued with a series of suggestions on how to help change the status quo. She also pointed out that there isn’t much incentive for Computer Scientists to become teachers. They will make far more money in the software industry than teaching. This is a serious problem. Why can’t some of our top tech companies help fix this problem? They certainly can afford to!
Guido’s Q&A

Guido’s talk was very entertaining. His entire talk was an extended Q&A. He started off by live coding a random question chooser to pick questions from twitter. He then took questions from the audience, but only women, “because throughout the conference, I’ve been attacked by people with questions, and they were almost all men.” Overall, I found this keynote much more entertaining than his keynote last year, so I would definitely recommend watching it.
Fernando’s Keynote
In his keynote, Fernando told the story of how he started the IPython project. “It began as me trying to procrastinate a little bit on finishing my dissertation” he said. (See “Set your code free” for some useful information on running your own open source projects.). In addition to the IPython project, Fernando covered a lot of the progress made in the SciPy community as a whole over the last year.
Recommended Talks
The full list of talks can be found on pyvideo.org, but I’d like to highlight a few of my favorites.
Technical Onboarding

One great talk I attended was by Kate Heddleston & Nicole Zuckerman on technical onboarding. This talk was chock-full of practical advice. I’ll definitely be re-watching this video and taking detailed notes.
Moar Data!
Maybe I’m biased, but one of the most exciting things about PyCon was all of the data related talks! I still have a ton of them left to watch, but of the ones I’ve seen, my favorites are:
Diving into Open Data with IPython Notebook & Pandas
Enough Machine Learning to Make Hacker News Readable Again

How to Get Started with Machine Learning

Realtime predictive analytics using scikit-learn & RabbitMQ
Yes, I really like my own talk ;-).
I also highly recommend watching the lightning talks. They were all very high quality and packed with lots of great insights. I hope they expand the lightning talks next year; they’re an excellent use of time!
The Hallway Track
On the second day of the conference, I met in one of the open spaces with a bunch of other data people (Thanks Julia Evans for arranging this!). The guys at Plotly demoed their product, and Cameron Davidson-Pilon showed off his new project lifelines, a library for survival analysis, which I’ll definitely be having a closer look at in the future.
Sprinting
![]()
Finally my PyCon experience ended with 2 days of sprinting on the scikit-learn project. I started by updating the Travis-CI build system from Python 3.3 to Python 3.4. A simple task but one which was perfect for my first commit. Then Olivier Grisel helped me fix an issue I had found while working on my talk. Contributing to scikit-learn was made really easy by both scikit-learn’s solid test coverage/CI system, and by the help of Olivier. Overall it seems like an extremely well run project which I can recommend getting involved in if you have the opportunity. If you’re interested in getting involved, I recommend checking out the issue tracker and looking for “Easy” issues. Another good place to look is pull requests that are ready to merge. Reviewing open pull requests and testing them out in your environment is always helpful.
See You Next Year!
Montreal is an awesome town and a great place for a conference. I ate lots of poutine and met a ton of awesome people! To all the awesome people I met, I hope to see you next year in Montreal!